Procena stepena i vrste izborne prevare pomoću modela konačne mešavine (eng. finite mixture models)
Uvod
Jedan od najnaprednijih pristupa u forenzici izbora je primena statističkog modeliranja, odnosno konstrukcija modela koji ocenjuje verovatnoću da je neko biračko mesto izloženo različitim vrstama manipulacije. U fokusu ovog pristupa je tzv. model konačne mešavine (eng. finite mixture model), koji kombinuje više „skrivenih“, latentnih kategorija (npr. normalno glasanje bez prevare, priraštaj prevare, ekstremna prevara) i pokušava da oceni za svako biračko verovatnoću svake od tih latentnih kategorija, odn. tip prevare/manipulacije.
Ovaj pristup je značajno razvijen u radovima profesora Williama Mebanea, koji je izgradio model sposoban da:
- klasifikuje biračka mesta po tipu prevare,
- kvantifikuje koliko je glasova verovatno dodato ili poništeno,
- identifikuje vrstu prevare (priraštaj prevare prema ekstremnoj prevari),
- radi čak i kada su dostupni samo agregirani rezultati.
U ovoj objavi dajemo sasvim kratko objašnjenje ovog metodološkog pristupa, dok će se u posebnoj seriji objava izložiti teorijske osnove i praktična primena modela konačne mešavine sa programom koji omogućava ocenu modela kako na osnovu simuliranih tako i na osnovu realnih izbornih rezultata.
Intuitivno objašnjenje
Zamislite da imate rezultate za hiljade biračkih mesta: broj registrovanih birača, izlaznost i broj glasova za određene kandidate. Neki rezultati deluju „normalno“, dok drugi odstupaju, ali nije lako reći koji su lažni, a koji samo neobični.
Model mešavine pokušava da „nauči“ obrasce u podacima i zatim podeli podatke u tri (ili više) kategorije:
- “Normalni”/regularni rezultati – biračka mesta bez prevare/manipulacija.
- Priraštaj prevare/Inflacija izlaznosti – dodati fiktivni birači, ali bez promene glasova (eng. incremental fraud/ballot stuffing).
- Ekstremna prevara/Inflacija rezultata – dodati glasovi za određenog kandidata (eng. extreme fraud).
Model zatim procenjuje, za svako biračko mesto, verovatnoću da pripada svakoj od ovih kategorija, kao i ukupan broj mesta ili glasova pod sumnjom.
Teorijska osnova
Osnovna struktura Mebaneovog modela može se predstaviti kao mešavina latentnih klasa. Pretpostavimo da je posmatran vektor podataka za biračko mesto \(i\): \(y_i = (t_i, v_i)\)
Gde je:
- \(t_i\) – broj izašlih birača u procentima (eng. turnout),
- \(v_i\) – broj glasova za određenog kandidata u procentima od broja važećih listića (eng. vote count).
Model pretpostavlja da ovi podaci dolaze iz mešavine tri rasporeda:
\(f(y_i) = \pi_1 f_1(y_i) + \pi_2 f_2(y_i) + \pi_3 f_3(y_i)\)
Gde je:
- \(\pi_k\) – proporcija opservacija u komponenti \(k\) (npr. bez prevare, priraštaj prevare, ekstremna prevara),
- \(f_k\) – zakon verovatnoće za svaku komponentu.
Rasporedi \(f_k\) se modeliraju pomoću beta-binomialnog rasporeda:
\(t_i \sim \text{Binomial}(n_i, \theta_t), \quad v_i \sim \text{Binomial}(t_i, \theta_v)\)
gde \(\theta_t\) i \(\theta_v\) variraju u zavisnosti od klase (npr. više vrednosti za klase koje predstavljaju prevaru).
Model se optimizuje putem korišćenja OM algoritma očekivanje-maksimizacija (eng. EM – expectation-maximisation). To je dvostepena iterativna metoda koja se koristi za pronalaženje (lokalnih) ocena maksimalne verodostojnosti ili maksimalnih aposteriornih ocena parametara u statističkim modelima koji zavise od neobservabilnih podataka ili latentnih promenljivih. Osnovna ideja je rešavanje problema gde je direktna ocena parametara (kao što je ocena maksimalne verodostojnosti) računski nerešiva jer neki relevantni podaci nedostaju ili su skriveni. Algoritam se smenjuje između dva koraka (očekivanja i maksimizacije) sve dok ocene parametara ne konvergiraju.
Tipovi manipulacija koje otkriva
Mebaneov model omogućava eksplicitno razlikovanje između:
- Inflacije izlaznosti (ballot-stuffing): dodat je broj birača koji su „glasali“, ali nisu nužno dali glas.
- Inflacije rezultata: broj glasova za jednog kandidata veštački je uvećan.
- Kombinovane manipulacije: oba fenomena se javljaju zajedno.
Model takođe omogućava kvantifikaciju koliko je ukupno glasova pod sumnjom, a to je ključno za određivanje da li bi prevara mogla promeniti ishod izbora.
Primena u Excel-u i R-u
❌ Excel:
Primena ovakvih modela nije moguća u Excel-u.
✅ R:
Mebane koristi svoj R paket electionforensics i dodatne procedure pisane u R i Python jeziku. Za pojednostavljenu ilustraciju koristi se flexmix, nnet, ili ručna konstrukcija verovatnosnog modela.
Primer (pojednostavljen):
# Instalacija paketa (ako nije instaliran)
install.packages("flexmix")
library(flexmix)
# Simulacija podataka
set.seed(123)
n <- 1000
df <- data.frame(
izlaznost = rbeta(n, 2, 5),
glasovi = rbeta(n, 3, 4)
)
# Model mešavine sa 3 komponente
model <- flexmix(cbind(izlaznost, glasovi) ~ 1, data = df, k = 3, model = FLXMCmvnorm())
summary(model)
parameters(model)Dobija se sledeći rezultat:
> summary(model)
Call:
flexmix(formula = cbind(izlaznost, glasovi) ~ 1, data = df, k = 3, model = FLXMCmvnorm())
prior size post>0 ratio
Comp.1 0.379 309 1000 0.309
Comp.2 0.187 215 546 0.394
Comp.3 0.434 476 976 0.488
'log Lik.' 784.9992 (df=14)
AIC: -1541.998 BIC: -1473.29
> parameters(model)
Comp.1 Comp.2 Comp.3
center.izlaznost 0.42674335 0.101141365 0.251485516
center.glasovi 0.43175088 0.415611419 0.448260301
cov1 0.02083088 0.002067577 0.007507452
cov2 0.00000000 0.000000000 0.000000000
cov3 0.00000000 0.000000000 0.000000000
cov4 0.02998656 0.031264316 0.031611787Ovde dajemo kratku analizu dobijenog rezultata. Prvo, funkcijom flexmix(formula = cbind(izlaznost, glasovi) ~ 1, data = df, k = 3, model = FLXMCmvnorm()) tražimo da se oceni model mešavine sa tri komponente na osnovu multivarijacionog normalnog rasporeda (za to koristimo FLXMCmvnorm()) za dvodimenzione podatke (izlaznost, glasovi). ~ 1 znači da se ne koriste objašnjavajuće promenljive; jednostavno se modeliraju srednje vrednosti i kovarijanse unutar svake od tri grupe/klastera.
Prva tabela daje objašnjenje elemenata u prvoj tabeli rezultata.
| Element | Značenje |
|---|---|
| prior | Ocenjena proporcija mešavine ili ponder/težina svake komponente (zbir do 1). Na primer, komponenta 1 čini ~38% podataka. |
| size | Broj posmatranja dodeljenih (najverovatnije) ovoj komponenti. Npr., 309 u Komponenti 1 (od ukupnog broja n=1000). |
| post>0 | Broj posmatranja sa nenultom aposteriornom verovatnoćom pripadnosti ovoj komponenti (meka dodeljivanja). Za Komponentu 1, svih 1000 posmatranja imaju neku verovatnoću (>0) da pripadaju ovde (309 je dodeljeno kao najverovatnije). |
| ratio | Veličina podeljena sa posteriornom verovatnoćom >0, prikazuje prosečnu dominantnu snagu dodeljivanja. Npr., 0,309 znači da je ~30,9% posmatranja sa bilo kojom pripadnošću Komponenti 1 prvenstveno dodeljeno njoj. |
Ovi rezultati odražavaju prirodu mekog grupisanja OM algoritma.
- log Lik. = 784.9992 (df=14): Maksimalna vrednost logaritma funkcije verodostojnosti finalnog modela sa 14 stepeni slobode.
- AIC = -1541.998: Akaike informacioni kriterijum (eng. Akaike Information Criterion) balansira dobru prolagođenost modela i njegovu kompleksnost (merenu brojem ocenjenih parametara) – poželjna je niža vrednost kada se porede dva i više modela.
- BIC = -1473.29: Bajesov informacioni kriterijum (eng. Bayesian Information Criterion), još jedna mera prilagođenosti modela – poželjna je niža vrednost.
Ovi informacioni kriterijumi izbora modela se koriste kada se vrši izbor između konkurentnih broja komponenti u modelu ili između alternativnih specifikacija modela.
Druga tabela daje objašnjenje elemenata u drugoj tabeli rezultata.
| Parametri | Comp. 1 | Comp. 2 | Comp. 3 |
|---|---|---|---|
| center.izlaznost | 0.426743 | 0.101141 | 0.251486 |
| center.glasovi | 0.431751 | 0.415611 | 0.448260 |
| cov1 | 0.020831 | 0.002068 | 0.007507 |
| cov2 | 0.000000 | 0.000000 | 0.000000 |
| cov3 | 0.000000 | 0.000000 | 0.000000 |
| cov4 | 0.029987 | 0.031264 | 0.031612 |
U tabeli su dati ocenjeni parametri za svaku grupu/klaster:
center.izlaznostandcenter.glasovi: Ocenjene srednje vrednosti dve promenljive u okviru svake komponente.- Npr., Comp1 srednja vrednost za izlaznost je ~0.427, a za osvojene glasove ~0.432.
cov1,cov4: Elementi kovarijacione matrice za dvodimenzionalni normalni raspored za svaku komponentu.
Ovde su cov2 i cov3 jednaki nuli, što ukazuje na dijagonalnu kovarijansu (nema kovarijanse između izlaznosti i glasova). Dijagonalni članovi (cov1, cov4) predstavljaju varijansu „izlaznosti“ i „glasova“ unutar svake komponente. Na primer, komponenta 1 ima varijansu izlaznosti ~0,0208, glasova ~0,0300.
Rezime: Model je podelio podatke u 3 latentne grupe/klastere sa proporcijama od oko 38%, 19% i 43%. Svaka grupa ima svoju srednju vrednost i strukturu varijanse za „izlaznost“ i „glasove“. Matrice kovarijanse su dijagonalne, što implicira nezavisno modeliranje izlaznosti i glasova unutar komponenti. Posteriorne meke dodele odražavaju OM neizvesnost. Statistika prilagođavanja modela (AIC/BIC) može se koristiti za poređenje sa drugim modelima ili brojem komponenti.
R kod za grafički prikaz rezultata.
library(flexmix)
library(ggplot2)
library(ellipse) # za crtanje elipsi kovarijansi
# Izdvajanje dodela grupa (tvrda klasifikacija)
clusters <- clusters(model)
df$grupe <- factor(clusters)
# Osnovni dijagram rasturanja obojem prema grupama
p <- ggplot(df, aes(x = izlaznost, y = glasovi, color = grupe)) +
geom_point(alpha = 0.5) +
theme_minimal() +
labs(title = "Dijagram rasturanja izlaznosti prema osvojenim glasovima sa članstvom u grupama")
# Za svaku grupu crtati elipse kovarijansi
params <- parameters(model)
for (k in 1:3) {
center <- c(params[paste0("center.izlaznost"), k], params[paste0("center.glasovi"), k])
covm <- matrix(c(params[paste0("cov1"), k], 0, 0, params[paste0("cov4"), k]), ncol = 2)
ell <- as.data.frame(ellipse(covm, centre = center, level = 0.95))
p <- p + geom_path(data = ell, aes(x = x, y = y), color = scales::hue_pal()(3)[k], size = 1)
}
print(p)Slika 1 ilustruje rezultat ocene modela konačne mešavine.
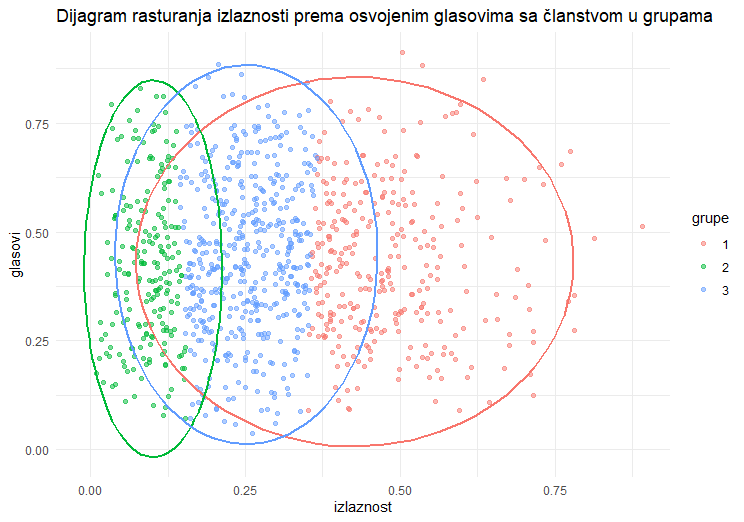
Napomena: Za ozbiljnu primenu, potrebni su podaci po biračkom mestu: broj registrovanih, broj izašlih, broj glasova po kandidatu. Mebaneova metodologija uključuje i grafičke dijagnostike: dijagram rasturanja izlaznosti prema udelu osvojenih glasova po klasi. Kao što je rečeno, kompletni R programi koji omogućavaju ocenu modela na osnovu realnih i simuliranih podataka biće dati u posebnoj objavi.
Realne primene i reference
🟩 Iran 2009.
U radu „Fraud in the 2009 Presidential Election in Iran?“ Mebane je primenio ovaj model i procenio da je značajan broj biračkih mesta pokazivao karakteristike inflacije rezultata. Procena je pokazala da je oko 5–15% biračkih mesta bilo pogođeno prevarom, što je moglo uticati na ishod izbora.
Mebane, W. R. (2010). Fraud in the 2009 presidential election in Iran? Chance, 23(1), 6–15.
https://doi.org/10.1080/09332480.2010.10739775
Zaključak
Statističko modeliranje putem modela konačne mešavine, kao što je pristup Williama Mebanea, predstavlja najjaču dostupnu tehniku za kvantitativnu ocenu izborne prevare na velikim skupovima podataka. Umesto pukog identifikovanja anomalija, ovaj metod omogućava klasifikaciju, kvantifikaciju, i evaluaciju uticaja manipulacija.
Iako zahteva naprednija znanja u statistici, može se koristi kao alat za izborne komisije, nezavisne posmatrače i istraživače koji žele objektivan dokaz postojanja sistematske nepravilnosti.