1. Uvod
U ovom serijalu već smo videli da jedan test retko “presuđuje”, ali više jednostavnih signala zajedno često daje vrlo upotrebljivu mapu rizika. „Aproksimativna normalnost“ je upravo takav alat: umesto da gledamo samo proseke ili korelacije, posmatramo oblik raspodele izbornih rezultata po biračkim mestima. Ideja (u formi koju koristi Klimek i saradnici) je da se rezultati pobednika transformišu i standardizuju tako da postanu uporedivi kroz izbore i zemlje; zatim se gleda koliko ta standardizovana raspodela liči na standardnu normalnu. Velika odstupanja ne dokazuju manipulaciju, ali mogu biti signal da se “nešto sistematski dešava” i da vredi preći sa statistike na proveru zapisnika i terenskih nalaza.
2. Teorijska i intuitivna osnova
Šta tačno znači “aproksimativna normalnost”?
Intuicija je jednostavna: kada se izborni ishod na nivou biračkog mesta formira pod uticajem velikog broja manjih faktora (lokalne preferencije, struktura birača, mobilizacija, kampanja, logistika), “zbir efekata” često daje raspodele koje, posle odgovarajuće transformacije, izgledaju približno kao normalne (ne savršeno, ali prepoznatljivo). Poenta nije da izbori “moraju” biti normalni, već da neke vrste sistematskih pomeranja mogu ostaviti trag u obliku raspodele (vrh, repovi, asimetrija).
Klimekova definicija varijable (ključna stvar)
Klimek i saradnici ne rade direktno sa procentom glasova, već sa transformacijom “logaritamske stope glasova pobednika” (zapravo logit broja glasova pobednika u odnosu na “ne-pobednika” u okviru izborne jedinice): \(\nu_i=\log\left(\frac{W_i}{N_i-W_i}\right)\)
gde je \(W_i\) broj glasova za pobedničku listu u jedinici \(i\), a \(N_i\) broj glasača (u praksi u našim podacima to tipično preslikavamo na upisane birače po biračkom mestu). Ako je \(W_i=0\) ili \(W_i\ge N_i\), \(\nu_i\) nije definisan i takve jedinice se izostavljaju.
Zatim se radi standardizacija radi poređenja: \(z_i=\frac{\nu_i-\overline{\nu}}{sd(\nu)}\)
što daje raspored sa sredinom 0 i varijansom 1 (“isti jezik skale” za upoređivanje kroz zemlje i izborne cikluse).
Kako se čita odstupanje od normale?
U tvom nacrtu je naglašeno nekoliko tipičnih odstupanja:
- viši vrh (leptokurtičnost): previše jedinica “nagurano” oko centralne vrednosti,
- debeli repovi: previše ekstremnih jedinica,
- asimetrija ili “ramena”: moguća mešavina više režima (legitimna heterogenost ili sistematski efekat).
👉 I opet: to je indikator za proveru, ne dokaz.
3. Primena u forenzici izbora
(a) Poređenje izbora i zemalja na istom nivou agregacije
Najveća vrednost metode je “preklapanje podataka”: posle transformacije i standardizacije, rasporedi različitih izbora postaju direktno uporedivi. Postaje vidno da li neki izbor “iskače” (npr. izrazito viši vrh ili repovi) u odnosu na uobičajene obrasce.
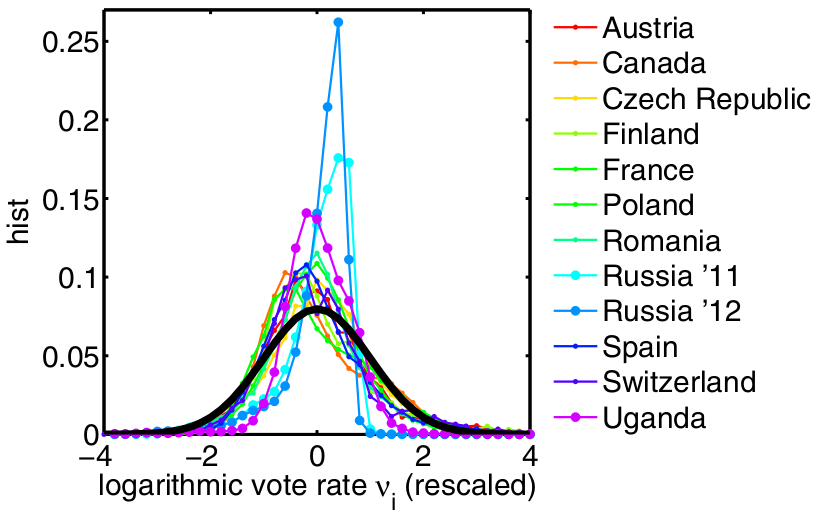
(b) Trijaža / Screening
Ako oblik raspodele deluje neuobičajeno, sledeći korak nije “zaključak”, već lista praktičnih provera: gde su ekstremi, da li su prostorno koncentrisani, da li se poklapaju sa drugim signalima (okrugli procenti, testovi na osnovu cifara, otisci prstiju/konture) i sa terenskim izveštajima.
(c) Kombinovanje sa ostalim alatima iz serijala
Ova metoda odlično “sarađuje” sa:
- izbornim otiscima prstiju/konturama (2D vizuelni obrasci),
- kumulativnim dijagramima (uvid u raspored izlaznosti i osvojenih glasova),
- testovima na osnovu cifara i “okruglim procentima” (indikator ljudske sklonosti ka zaokruživanju).
4. Ograničenja i kritike
- Normalnost nije obaveza. Legitimna heterogenost (regionalne i urbano-ruralne podele, specifična biračka mesta, različiti tipovi kampanje) može prirodno praviti “mešavine” i repove.
- Zavisnost od agregacije. Na nivou biračkog mesta dobijate drugačiju sliku nego na nivou opština.
- Granični slučajevi i definicije. Klimekova transformacija traži \(W_i\) i \(N_i\); ako radite samo sa procentima, morate uvoditi pretpostavke koje u ovoj analizi nisu preporučljive.
- Testovi normalnosti u velikim uzorcima. Formalni testovi često odbacuju normalnost i za male, praktično nebitne devijacije. U praksi je važniji oblik + robustnost kroz alternative (npr. različite podskupove) nego p-vrednost.
5. Praktična komponenta (Excel/R)
A) ✅ Excel (minimalistički, Klimek-konzistentno)
Pretpostavka: imate kolone
precinct_size= upisani birači (to je \(N_i\))
broj glasova pobedničke liste (to je \(W_i\))- opciono:
turnout_pct,winner_pct(za kontekst)
Korak 1: izračunaj \(\nu_i\)
U Excel-u (primer logike):
- Ako je
winner_votes> 0 iwinner_votes<precinct_size, računaj:
=LN(winner_votes/ (precinct_size - winner_votes) ) - U suprotnom ostavi prazno (izostavi tu jedinicu).
Korak 2: standardizuj \(z_i\)
z= (nu–AVERAGE(nu)) /STDEV.S(nu)
Korak 3: histogram i “normalna kriva”
- Napravi histogram
z. - Napravi mrežu od -4 do 4 (npr. korak 0.1), izračunaj
NORM.S.DIST(grid, FALSE)i nacrtaj liniju preko histograma (ili pored, kao referencu).
👉 Kako čitati: da li je histogram vidno “šiljatiji” od normalnog rasporeda, ima li deblje repove, asimetriju.
B) ✅ R (tidyverse + ggplot2)
# Pretpostavi df sa kolonama: precinct_size, winner_votes, turnout_pct, winner_pct.
library(dplyr)
library(ggplot2)
# 1) Klimekova transformacija: nu_i = log( W_i / (N_i - W_i) )
df2 <- df %>%
filter(
!is.na(precinct_size), !is.na(winner_votes),
winner_votes > 0,
winner_votes < precinct_size
) %>%
mutate(
nu = log(winner_votes / (precinct_size - winner_votes))
) %>%
mutate(
z = (nu - mean(nu, na.rm = TRUE)) / sd(nu, na.rm = TRUE)
)
# 2) Histogram + standardna normalna gustina
p_hist <- ggplot(df2, aes(x = z)) +
geom_histogram(aes(y = after_stat(density)), bins = 40) +
stat_function(fun = dnorm, linewidth = 1) +
labs(
title = "Aproksimativna normalnost (Klimek): standardizovani logaritamski vote-rate pobednika",
x = "z = (nu - mean(nu)) / sd(nu)",
y = "Gustina"
) +
theme_minimal(base_size = 12)
print(p_hist)
# 3) QQ-plot (opciono)
p_qq <- ggplot(df2, aes(sample = z)) +
stat_qq() +
stat_qq_line() +
labs(
title = "QQ-plot u odnosu na standardnu normalnu",
x = "Teorijski kvantili",
y = "Empirijski kvantili"
) +
theme_minimal(base_size = 12)
print(p_qq)
# 4) Skewness/kurtosis (bez dodatnih paketa; uzorak kurtosis = "excess" + 3 po potrebi)
m <- mean(df2$z)
s <- sd(df2$z)
skew <- mean(((df2$z - m)/s)^3)
kurt <- mean(((df2$z - m)/s)^4) # ovo je "kurtosis"; excess = kurt - 3
c(skewness = skew, kurtosis = kurt, excess_kurtosis = kurt - 3)👉 Napomena: formalni testovi normalnosti nisu prioritet; važniji su oblik i poređenje.
6. Analiza slučaja: Parlamentarni izbori 2023 (Srbija)
U standardnom primeru serijala posmatramo parlamentarne izbore u Srbiji 2023 na nivou biračkog mesta, za pobedničku listu SNS (nosilac Aleksandar Vučić). Poređenje sa drugim izbornim ciklusom iz 2022. godine koristi se samo kao demonstracija primene metode.
Kada se prikaže standardizovana raspodela \(z_i\), vidi se da je kriva “višeg vrha” u odnosu na standardan normalan raspored, dakle, postoji odstupanje, ali ono nije ekstremno kao u “jačim” ilustrativnim slučajevima koji se često navode u kontekstu rada Klimeka i saradnika (npr. Rusija/Uganda u njihovim prikazima).
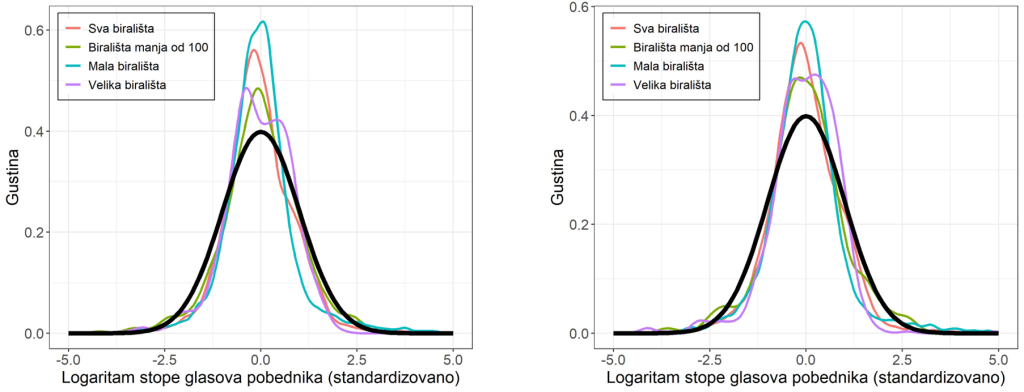
Na Slici 2 obrasci za 2022 i 2023 vrlo slični, što je korisno upravo kao “primena metode”: ako je oblik stabilan kroz cikluse, to je informacija sama po sebi (o stabilnosti procesa ili stabilnosti strukturnih heterogenosti).
Opciona provera robustnosti: mala vs velika biračka mesta
Može se proveriti da li se oblik rasporeda razlikuje po veličini BM. Mala BM mogu imati “drugačiji” obrazac u odnosu na velika, što je upravo tip pitanja koje statistički signal treba da otvori, a zatim da se proveri dokumentima i terenom.
Viši vrh znači da je više biračkih mesta “nagurano” oko centralne vrednosti transformisanog rezultata pobednika; debeli repovi znače više ekstremnih BM nego što bi normalna kriva sugerisala. To može biti kompatibilno sa različitim mehanizmima (uključujući problematične), ali isto tako može doći do heterogenosti. Dakle, u pitanju može biti signal za proveru, a ne dokaz.
OKVIR 2 — Lista za proveru: od signala do provere
- Identifikuj ekstremne BM (repovi) i proveri zapisnike: konzistentnost brojeva (upisani–izašli–važeći–nevažeći).
- Proveri prostornu koncentraciju ekstremnih BM.
- Upari sa drugim alatima: otisci prstiju/konture, kumulativni dijagram, testovi na osnovu cifara i “okrugli procenti”.
- Uradi opcionu proveru robustnosti po veličini BM (posebno mala BM) i upari sa posmatračkim izveštajima i prigovorima.
7. Zaključci i preporuke za posmatrače i analitičare
- Koristi Klimekovu transformaciju kada imaš brojeve \(W_i\), \(N_i\); sa procentima metoda lako sklizne u pretpostavke.
- Ne traži “savršenu normalnost”, traži upadljive promene oblika i stabilnost/razliku kroz cikluse.
- Uvek uradi bar jednu internu proveru robustnosti (npr. po veličini BM), ali je komuniciraj kao validaciju, ne kao presudu.
- Nemoj se oslanjati na jedan alat: aproksimativna normalnost je najbolja kao deo “paketa” (otisci prstiju/konture + kumulativni + testovi na osnovu cifara + teren).
- U javnoj komunikaciji koristi jezik “indikator”, “signal”, “zahteva proveru”, uz jasnu napomenu o alternativnim objašnjenjima.
8. Literatura
- Borghesi, C., Chiche, J., & Nadal, J.-P. (2012). Election turnout statistics in many countries: Similarities, differences, and a diffusive field model for decision-making. PLOS ONE, 7(5), e36289. https://doi.org/10.1371/journal.pone.0036289
- Chatterjee, A., Mitrović, M., & Fortunato, S. (2013). Universality in voting behavior: an empirical analysis. Scientific Reports, 3, 1049. https://doi.org/10.1038/srep01049
- Fortunato, S., & Castellano, C. (2007). Scaling and universality in proportional elections. Physical Review Letters, 99, 138701. https://doi.org/10.1103/PhysRevLett.99.138701
- Klimek, P., Yegorov, Y., Hanel, R., & Thurner, S. (2012). Statistical detection of systematic election irregularities. Proceedings of the National Academy of Sciences, 109(41), 16469–16473. https://doi.org/10.1073/pnas.1210722109
- Kobak, D., Shpilkin, S., & Pshenichnikov, M. S. (2016). Integer percentages as electoral falsification fingerprints. The Annals of Applied Statistics, 10(1). https://doi.org/10.1214/16-AOAS904