1. Uvod
U izbornim podacima često je najkorisnije krenuti od najprostijih stvari: kako izgleda raspored izlaznosti po biračkim mestima i kako izgleda raspored rezultata pobedničke liste po biračkim mestima. Ovi histogrami su “bazični instrument” u tradiciji ruske izborne forenzike povezane sa Sergejem Špiljkinom, jer na jednom mestu mogu da otkriju obrasce koje je teško videti u tabelama: zadebljane desne repove, pomeranje raspodele kroz vreme, i naročito “šiljke” na okruglim procentima.
Poenta nije da histogram “dokazuje” manipulaciju. Poenta je da histogram pomaže da se napravi lista pitanja: gde su ekstremi, da li su prostorno koncentrisani, da li se ponavljaju na okruglim vrednostima, i da li se obrazac menja kroz izborne cikluse. Ovo je tipičan “screening” alat koji zatim treba upariti sa zapisnicima, posmatračkim izveštajima i drugim metodama iz serijala.
2. Teorijska i intuitivna osnova
Šta tačno gledamo?
Konstruišemo dva histograma na nivou biračkog mesta (BM):
- Raspored izlaznosti: histogram
turnout_pct(izašli/upisani, 0–100). - Raspored rezultata pobednika: histogram
winner_pct(pobednička lista u važećim glasovima, 0–100).
Intuicija “glatke” raspodele
Ako izlaznost i izborni rezultat variraju po BM (različite lokalne preferencije, socio-demografija, urbano-ruralne razlike), raspored će često biti relativno gladak: nema naglih diskontinuiteta, a vrednosti u susednim klasnim intervalima ne “iskaču” dramatično. Primer rasporeda izbornih rezultata u Poljskoj 2005. godine je ilustracija takvog obrasca.
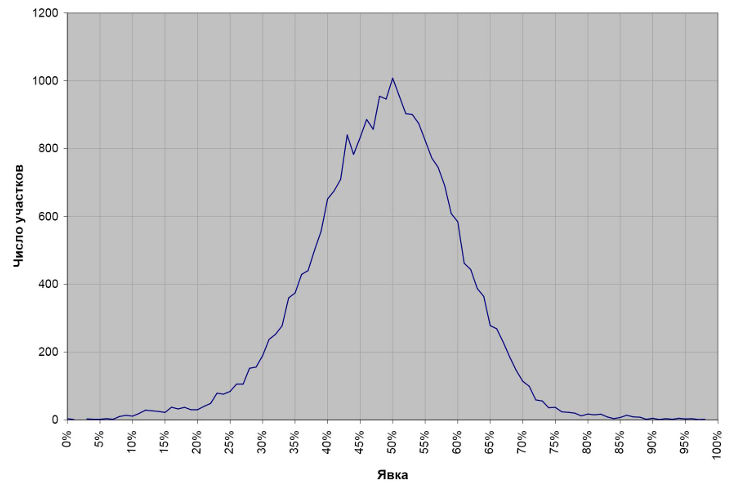
Izvor: Шень (2020, s. 13)
Šta su “šiljci” i zašto su zanimljivi?
Šiljak znači: iznenada mnogo vrednosti u klasnim intervalima koji su tačno na okrugloj vrednosti (npr. klasni intervali na 60%, 65%, 75%…). Špiljkinov argument je da, ako je proces izveštavanja “prirodan”, ne bi trebalo da postoji preferencija ka baš tim tačkama; dok kod falsifikovanja/ručne korekcije ili administrativnog zaokruživanja može postojati “ljudska privlačnost” ka okruglim brojevima.
Desni rep i pomeranje udesno
U literature se navode i dva dodatna znaka: (1) raspored se iz ciklusa u ciklus “gura udesno”, i (2) desni rep postaje deblji (više BM sa vrlo visokom izlaznošću i/ili vrlo visokim rezultatom pobednika). U ekstremnim slučajevima može se pojaviti i bimodalnost.
3) Primena u forenzici izbora
(a) Trijaža (Screening / flagging)
Histogrami su odlični za “trijažu”:
- Visoke vrednosti u klasni intervalima u repovima (npr. izlaznost 90–100) i
- Klasni intervali sa šiljcima (npr.
winner_pct= 75)
postaju kandidati za proveriti kroz zapisnike i lokalni kontekst.
(b) Poređenje kroz vreme (isti nivo agregacije)
Kada nacrtaš rasporede za dve izborne godine, gledaš:
- da li se krive pomeraju udesno,
- da li repovi rastu,
- da li se šiljci pojavljuju/jačaju.
Ovo je jedna od praktično najvrednijih upotreba ovog alata: isti “instrument” kroz vreme.
(c) Kombinovanje sa drugim alatima
Rasporedi su najmoćniji alati u paketu sa:
- otiscima prstiju/konturnim dijagramom (2D slika izlaznost × glasovi pobednika),
- aproksimativnom normalnošću (transformisan raspored),
- testovima na osnovu cifara (npr. “celobrojni procenti” i srodne ideje),
- kumulativnim dijagramima.
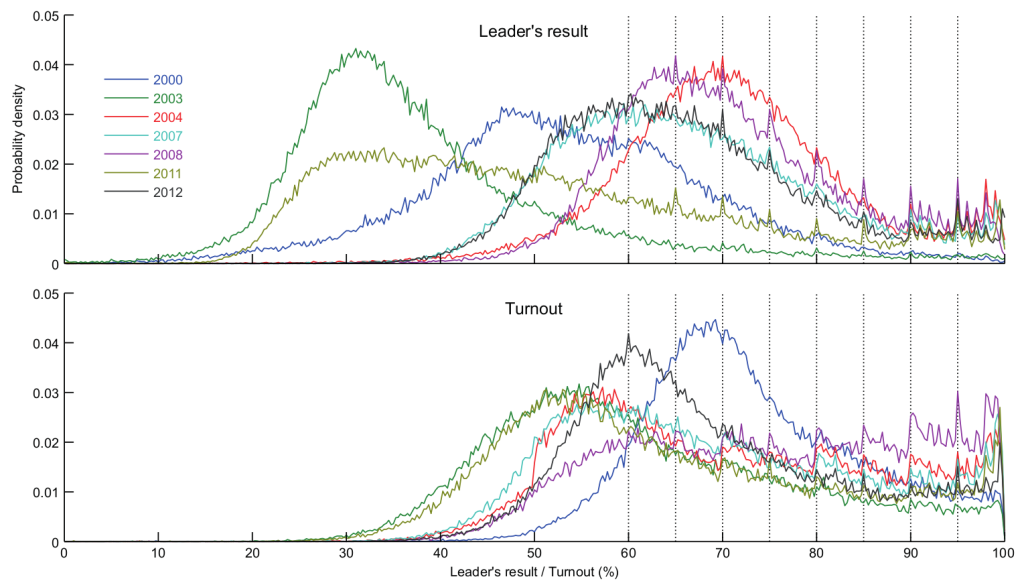
4. Ograničenja i kritike
- Legitimna heterogenost: repovi mogu biti realni (npr. specifične zajednice, urbani/ ruralni kontrast, lokalna mobilizacija). Rep sam po sebi nije dokaz.
- Administrativni efekti: šiljci mogu nastati i iz praksi izveštavanja ili zaokruživanja, ne nužno iz direktnog “ubacivanja listića”.
- Klasni intervali i mali uzorak: kod manjih brojeva biračkih mesta, preuski klasni intervali mogu proizvesti “veštačke” šiljke koji su samo statistički šum. Zato izbor širine klasnog intervala mora biti pragmatičan (vidi sledeću tačku).
- Signal, ne dokaz: histogram mora da vodi ka proveri (zapisnici, prostorna koncentracija, posmatrači), ne ka automatskom zaključku.
5. Praktična komponenta (Excel/R)
Ključna napomena o klasnim intervalima (obavezno pre crtanja)
Širina klasnog intervala zavisi od broja biračkih mesta. U ruskim federalnim izborima, sa ogromnim brojem BM, moguće je koristiti finu rezoluciju (npr. 0.25%) i dobiti stabilnu sliku. U Srbiji, sa znatno manjim brojem BM, preuski klasni intervali često daju mnoštvo “šiljkova” koji su samo posledica diskretnosti i malog uzorka. Zato je u ovoj analizi razumno uzeti da je širina klasnog intervala 2% (4% u slučaju izbora u Beogradu).
A) ✅ Excel (minimalistički)
Pretpostavimo da imamo tabelu podataka sa sledećim kolonama: turnout_pct i winner_pct.
- Histogram izlaznosti
- Klasni intervali: 0, 1, 2, …, 100 (ili 0, 2, 4,…,100 ako je previše “šumno”).
- Napravi histogram (Data Analysis Toolpak ili
FREQUENCY/COUNTIFSpristup).
- Histogram rezultata pobednika
- Isti princip: klasni intervali 0–100 sa 1% (ili 2%) intervalima.
- Označi okrugle procente
- Dodaj vizuelne markere na 50, 55, 60,…,100 (ili bar 60, 65, …, 100).
- Šiljak je kada je u vrednost u klasnom intervalu 65 znatno veći od vrednosti u klasnim intervalima 64 i 66 (u istoj skali).
- Kako čitati
- Da li ima repova ka visokim vrednostima?
- Da li postoje šiljci baš na multiplikatorima od 5%?
B) ✅ R (tidyverse + ggplot2)
Pretpostavi postojanje data frame (df) sa kolonama turnout_pct i winner_pct.
1) Histogrami sa stabilnom širinom klasnog intervala (podrazumevajuća vrednost je 1%)
df2 <- df %>%
filter(
!is.na(turnout_pct), !is.na(winner_pct),
between(turnout_pct, 0, 100),
between(winner_pct, 0, 100)
)
# Pragmatičan izbor binwidth-a:
# - default 1%
# - ako je uzorak mali i “zvoni”, probaj 2%
binw <- 1
p_turnout <- ggplot(df2, aes(x = turnout_pct)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = binw, boundary = 0, closed = "left") +
geom_vline(xintercept = seq(50, 100, by = 5), linetype = "dotted", linewidth = 0.4) +
labs(
title = "Raspored izlaznosti po biračkim mestima",
x = "Izlaznost (turnout_pct)",
y = "Gustina"
) +
coord_cartesian(xlim = c(0, 100)) +
theme_minimal(base_size = 12)
p_winner <- ggplot(df2, aes(x = winner_pct)) +
geom_histogram(aes(y = after_stat(density)),
binwidth = binw, boundary = 0, closed = "left") +
geom_vline(xintercept = seq(50, 100, by = 5), linetype = "dotted", linewidth = 0.4) +
labs(
title = "Raspored rezultata pobedničke liste po biračkim mestima",
x = "Udeo pobednika u važećim glasovima (winner_pct)",
y = "Gustina"
) +
coord_cartesian(xlim = c(0, 100)) +
theme_minimal(base_size = 12)
print(p_turnout)
print(p_winner)2) Jednostavan “poen šiljka” po klasnom intervalu
Ideja: uporedi gustinu u klasnom intervalu sa prosekom susedna dva klasna intervala.
make_spike_table <- function(x, binwidth = 1) {
breaks <- seq(0, 100, by = binwidth)
bins <- cut(x, breaks = breaks, include.lowest = TRUE, right = FALSE)
tab <- as.data.frame(table(bins), stringsAsFactors = FALSE)
tab$count <- tab$Freq
tab$Freq <- NULL
n <- length(x)
tab$density <- tab$count / (n * binwidth)
# spike = density(bin) - mean(density(neighbors))
tab$dens_lag <- dplyr::lag(tab$density)
tab$dens_lead <- dplyr::lead(tab$density)
tab$spike <- tab$density - (tab$dens_lag + tab$dens_lead) / 2
tab
}
sp_turnout <- make_spike_table(df2$turnout_pct, binwidth = binw)
sp_winner <- make_spike_table(df2$winner_pct, binwidth = binw)
# Top “šiljci” (ignorisi NA na ivicama)
sp_turnout %>% arrange(desc(spike)) %>% head(10)
sp_winner %>% arrange(desc(spike)) %>% head(10)3) Kratko o “protresanju” (eng. jitter) (provera robustnosti)
Kobak–Špiljkin–Pšenjičnikov pokazuju da diskretnost i ljudska sklonost ka okruglim brojevima mogu proizvesti “celobrojne procente/integer percentage” anomalije, i koriste trik dodavanja malog uniformnog šuma u brojioc pre računanja procenata kako bi se izbegli artefakti celobrojnih podela.
U našem kontekstu, ako imaš samo već izračunate procente, možeš uraditi približnu proveru robustnosti tako što “zatreseš” procente vrlo malo (npr. ±0.2 p.p.) i vidiš da li šiljci opstaju:
set.seed(1)
df_j <- df2 %>%
mutate(
turnout_j = pmin(100, pmax(0, turnout_pct + runif(n(), -0.2, 0.2))),
winner_j = pmin(100, pmax(0, winner_pct + runif(n(), -0.2, 0.2)))
)
# Ako šiljci nestanu posle jitter-a, mogu biti artefakt diskretizacije/klasnih intervala.
# Ako opstanu (u smislu: i dalje “iskaču” oko istih zona), signal je robusniji.👉 Napomena: protresanje/jitter nije “popravka podataka”, nego dijagnostička provera stabilnosti šiljaka.
6. Analiza slučaja: Parlamentarni izbori 2023 (Srbija)
Standardni primer serijala: parlamentarni izbori u Srbiji 2023, na nivou biračkog mesta, za pobedničku listu SNS čiji je nosilac Aleksandar Vučić. Ovde prikazujemo oba rasporeda: izlaznost i rezultat pobednika.
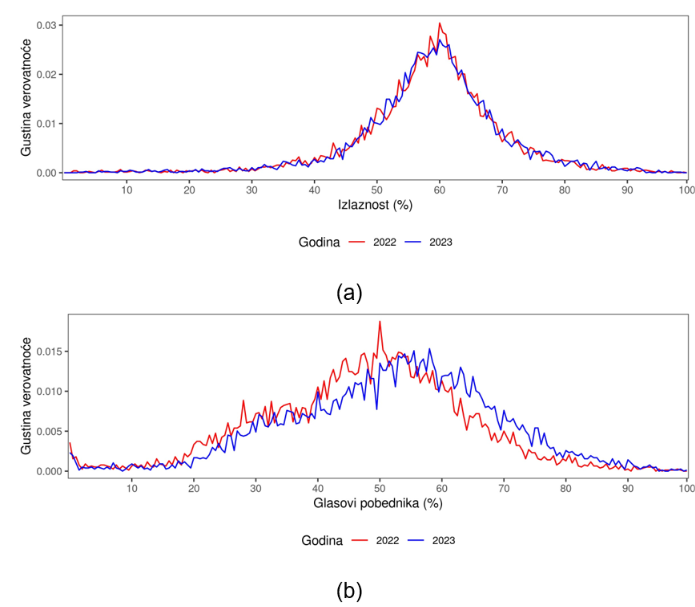
Grafikoni za Srbiju 2023 ne liče na ekstremne obrasce opisane za Rusiju (2000–2012), gde se vidi istovremeno pomeranje udesno i zadebljanje desnog repa, uz vidljive šiljke na 60, 65, …, 100.
Međutim, u 2023. godini se vidi fenomen šiljaka u raspodeli rezultata pobedničke liste (40%, 65% i 75%), što je upravo tip signala koji ovaj alat treba da “izvuče na površinu”. U idealno “glatkom” scenariju (poput ilustracije rasporeda na izborima u Poljskoj 2005) očekivali bismo znatno manje izražene lokalne skokove.
Poređenje sa 2022: obrasci 2022 i 2023 su prilično slični, uz blago pomeranje udesno raspodele 2023. U Špiljkinovom interpretativnom okviru, pomeranje udesno i jačanje repa/šiljaka kroz vreme tretira se kao indikator potencijalnog pogoršanja izborne demokratije, ali to i dalje ostaje indikator koji mora da se prove(zapisnici, terenski nalazi, prostorna analiza).
Šta proveriti kada vidiš šiljke ili repove:
- zapisnike (važeći/nevažeći, kontrolne sume),
- da li su BM sa šiljcima prostorno koncentrisani,
- da li se isti BM izdvajaju i u 2D prikazima (otisci prstiju/konture),
- da li postoji “celobrojni procenti/integer percentages” signal (okrugli procenti), i da li opstaje posle provere robustnosti “protresanjem”
OKVIR 1 — Šiljci na 5%: zašto su zanimljivi i šta NE dokazuju
Šiljci su zanimljivi jer mogu ukazivati na “privlačnost okruglih brojeva” u izveštavanju ili intervencijama. Ali šiljak sam po sebi ne dokazuje uzrok: može nastati i iz definicije klasnih intervala, diskretnosti, ili administrativnog zaokruživanja. Zato se šiljci tretiraju kao signal za proveru i testiraju robusno (npr. promenom širine klasnog intervala, proverom “protresanjem”).
OKVIR 2 — Lista provere: od histograma do provere
- Ponovi histogram sa širinom klasnog intervala 1% i 2%: da li šiljci opstaju?
- Uradi proveru “protresanja”: da li se “lokalni skokovi” isčezavaju ili ostaju?
- Izlistaj BM koji upadaju u sumnjive klasne intervale (npr. tačno 65%). Proveri zapisnike i kontrolne sume.
- Proveri prostornu koncentraciju (opštine/okrug).
- Uporedi sa 2D prikazima (otisci prstiju/konture) i testovima na osnovu cifara.
7. Zaključci i preporuke za posmatrače i analitičare
- Počni od dva histograma (izlaznost i glasovi pobednika): to je najbrža “slika stanja”.
- Širinu klasnog intervala prilagodi veličini uzorka: u Srbiji je 2% razumna podrazumevajuća vrednost, uži klasni intervali lako proizvodi šum.
- Šiljke tretiraj kao signal i uvek radi proveru robustnosti: promeni širinu klasnog intervala + uradi proveru “protresanjem”.
- Ne zaključuj o uzroku iz oblika rasporeda: konsultuj dokumente (zapisnike) i kontekst.
- Kombinuj sa drugim alatima: otisci prstiju/konture, aproksimativna normalnost, kumulativni dijagrami, testovi na osnovu cifara.
- Najveća vrednost ovog alata je u poređenju kroz vreme: “da li se repovi i šiljci pojačavaju ili slabe?”.
8. Literatura
- Klimek, P., Yegorov, Y., Hanel, R., & Thurner, S. (2012). Statistical detection of systematic election irregularities. Proceedings of the National Academy of Sciences, 109(41), 16469–16473. https://doi.org/10.1073/pnas.1210722109.
- Kobak, D., Shpilkin, S., & Pshenichnikov, M. S. (2016). Integer percentages as electoral falsification fingerprints. The Annals of Applied Statistics, 10(1). https://doi.org/10.1214/16-AOAS904.
- Kobak, D., Shpilkin, S., & Pshenichnikov, M. S. (2016). Statistical fingerprints of electoral fraud? Significance, 13(4), 20–23. https://doi.org/10.1111/j.1740-9713.2016.00936.x.
- Rozenas, A. (2017). Detecting election fraud from irregularities in vote-share distributions. Political Analysis, 25(1), 41–56. https://doi.org/10.1017/pan.2016.9.
- Jiménez, R., Hidalgo, M., & Klimek, P. (2017). Testing for voter rigging in small polling stations. Science Advances, 3(8), e1602363. https://doi.org/10.1126/sciadv.1602363.
- Шень, A. (2020). Выборы и статистика: казус «Единой России» (2009–2020). arXiv:1204.0307v4.