U prethodnim objavama objašnjeno je kako model konačne mešavine funkcioniše u teoriji i kako ga je Walter Mebane definisao kao okvir za razumevanje regularnih i sumnjivih obrazaca u izbornim podacima. Međutim, prava vrednost ovog pristupa dolazi tek kada se primeni na stvarne izbore. Empirijske studije pokazuju ne samo da model uspešno identifikuje sumnjive obrasce, već i da nudi precizne procene o tome koliki deo pobednikovih glasova potiče iz mesta za koja postoji indikacija manipulacije. U ovoj objavi u dva dela biće predstavljeni neki od najznačajnijih primera primene modela u različitim zemljama, što nam omogućava da sagledamo njegovu praktičnu moć i ograničenja.
Jedna od prvih i najpoznatijih primena modela konačne mešavine odnosi se na izbore u Rusiji. Ovi izbori su dugi niz godina bili predmet sumnji zbog karakterističnih anomalija u raspodelama izlaznosti i rezultata. Najpoznatiji fenomen su tzv. „šiljci“ na histogramima izlaznosti i rezultata, gde se primećuje neuobičajena koncentracija biračkih mesta na okruglim vrednostima kao što su 90% ili 100% izlaznosti, uz gotovo apsolutnu podršku vladajućem kandidatu. Vizuelno, ovi obrasci ukazuju na mogućnost ballot stuffinga ili administrativnog uvećavanja rezultata. Međutim, pitanje je koliko su ovi obrasci zaista značajni u pogledu ishoda. Kada se primeni Mebaneov model konačne mešavine, izlaznost i udeo glasova za pobednika tretiraju se kao dvodimenzionalni raspored koji generiše kombinacija regularnog i neregularnog procesa. Rezultati su pokazali da značajan procenat glasova za pobednika potiče iz sumnjivih klasa, često više od trećine ukupnog rezultata. Na ovaj način, model ne samo da potvrđuje postojanje anomalija, već i daje kvantitativni odgovor na pitanje o njihovoj težini i potencijalnom uticaju na legitimitet izbora.
Intuicija modela je jednostavna: regularna biračka mesta formiraju “glavno telo” rasporeda, dok inkrementalne i ekstremne nepravilnosti često stvaraju dodatne režime (grupe/klastere) u zonama visoke izlaznosti i/ili neuobičajeno visokog učešća osvojenih glasova pobednika. U prvom delu koristimo vizuelne forenzičke obrasce (toplotne mape) koje se konstruišu takođe na osnovu modela konačne mešavine, a zatim u drugom delu prelazimo na parametarske rezultate (tabele) koji razdvajaju mehanizme nepravilnosti na S (ukradeni, eng. stolen) i M (fabrikovani, eng. manufactured) komponente. Glasovi su ukradeni kada se glasovi za opoziciju preliju u glasove pobednika izbora. Glasovi su fabrikovani kada se listići koji nisu iskorišćeni (eng. nonvoters) dodaju glasovima pobednika.
4.1. “Izborni otisci prstiju”: Rusija (Klimek i sar., 2012)
Toplotne mape (2D gustine) su korisne jer ne nameću unapred formu raspodele: one prikazuju gde se najveći broj biračkih mesta “grupiše” u ravni (izlaznost × udeo pobednika). Klimek i saradnici pokazuju da se u nekim slučajevima pojavljuju karakteristični režimi: (i) regularno “jezgro”, i (ii) dodatna masa u visokoj izlaznosti i visokom udelu pobednika, što je često kompatibilno sa obrascima mobilizacije i/ili manipulacije.
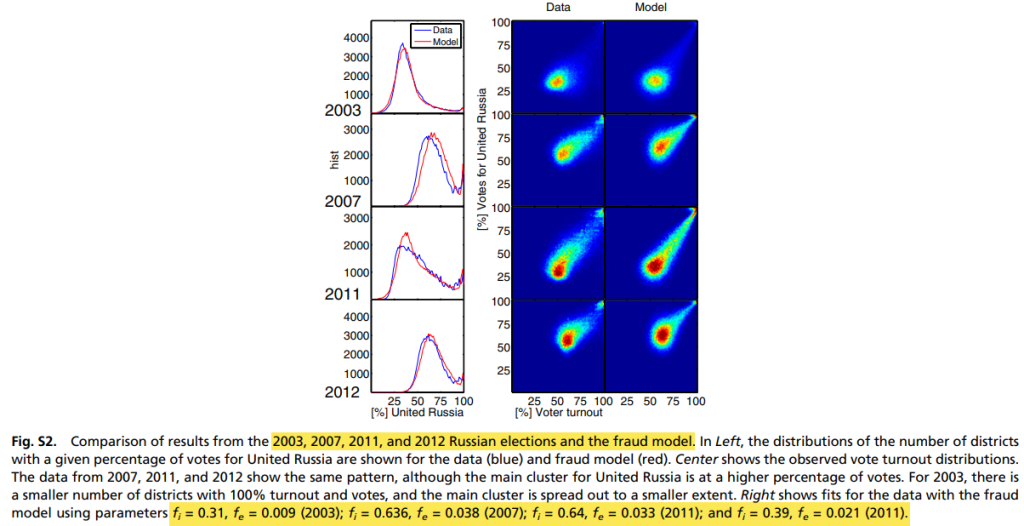
Slika 1 prikazuje uporedno: (i) toplotne mape na osnovu stvarnih izbornih rezultata i (ii) toplotne mape koje rekonstruiše model konačne mešavine (MKM). Fokus u čitanju ovih grafika je na tome koliko dobro model “uhvati” ključne obrasce u podacima, naročito karakteristične koncentracije biračkih mesta u zonama visoke izlaznosti i visokog udela pobednika. U literaturi se upravo takve koncentracije često povezuju sa obrascima nalik ballot stuffing-u ili administrativnom “pumpanju” rezultata. Na osnovu modela konačne mešavine dobijeno je npr. u 2012. godini da je inkrementalna prevara iznosila \(f_i = 39\%\), a ekstremna prevara \(f_e = 2.1\%\).
Važan dodatak (koji služi kao metodološki “kompas”) jeste ideja kako bi trebalo da izgledaju toplotne mape u slučaju poštenih izbora: u idealnom, “poštenom” scenariju, raspodela bi bila relativno glatka, bez oštrih i neprirodnih “vrhova” u ekstremima (npr. blizu 100% izlaznosti i 100% podrške). Upravo zato je korisno da se, pored rekonstrukcije na osnovu prilagođenog modela, ima u vidu i kontra primer: kakav je obrazac kad se pretpostavi odsustvo manipulacije.
Klimek-ov rad dodatno koristi komparativni pristup: isti tip vizuelizacije primenjuje se na zemlje sa različitim reputacijama izbornog integriteta. Time se dobija pragmatičan “vizuelni kriterijum”: kako izgleda “normalna” topologija rasporeda, a kako raspored sa sekundarnim režimima.
4.2. Uganda naspram Švajcarske: Model kao test “rekonstrukcije” i kontra primer
Uganda je još jedan slučaj gde je model konačne mešavine iskorišćen da se oceni integritet izbornih rezultata. U zemljama kao što je Uganda sa slabijim institucionalnim kapacitetima, nepravilnosti često poprimaju oblik ekstremnih rezultata na lokalnom nivou, gde lokalne vlasti imaju široku diskreciju u upravljanju procesom glasanja. Primena modela mešavine na ugandske izbore pokazala je da postoji veliki broj biračkih mesta sa gotovo potpunom podrškom vladajućem kandidatu i izlaznošću bliskom 100%. Procenat prevare u ovom slučaju bio je toliko visok da je jasno sugerisao da rezultat ne odražava regularnu izbornu dinamiku. Ovaj nalaz je bio posebno važan jer je omogućio međunarodnim organizacijama i lokalnim akterima da argumentuju svoje tvrdnje ne samo politički, već i statistički, oslanjajući se na rigorozan model.

Slika 2 je didaktički izuzetno čista: ista vizuelna logika koristi se za zemlju sa očiglednim problemima (Uganda) i za zemlju koja se često uzima kao primer stabilnog izbornog integriteta (Švajcarska). Prva kolona su toplotne mape iz realnih podataka, druga kolona su toplotne mape dobijene iz prilagođenog MKM-a (koliko dobro model rekreira realnost), a treća kolona su toplotne mape koje model implicira pod pretpostavkom poštenih i slobodnih izbora. u slučaju modela u trećoj koloni teorijski bi trebalo da je inkrementalna prevara \(f_i = 0\%\), kao i ekstremna prevara \(f_e = 0\%\).
- Uganda: tipično vidimo koncentraciju mase u gornjim zonama (visoka izlaznost + visoka podrška), a model u drugoj koloni, ako je dobro postavljen, treba da replicira te “vrhove”. Kada se pređe na kontra primer poštenioh izbora, tj. “fair” (treća kolona), očekuje se “spljoštenija” i umerenija raspodela. Što je veći jaz između realne i “fair” mape, to je interpretacija neregularnosti snažnija.
- Švajcarska: metodološki najvažnije, sve tri mape (realna, model-fitted, i fair) treba da budu relativno slične. Upravo to pokazuje da model nije “podešen da svuda nađe prevaru”, već da u uslovima urednih podataka prirodno daje nizak intenzitet neregularnih komponenti.
Zajednički imenitelj svih ovih primera jeste da model konačne mešavine uspeva da „prevede“ vizuelne i intuitivne sumnje u numeričke pokazatelje. Dok tradicionalne metode poput Benfordovog zakona često daju binarne rezultate (prisustvo ili odsustvo odstupanja od očekivane raspodele), a grafičke tehnike poput Klimekovih kumulativnih krivih ilustruju neuobičajene obrasce bez jasne kvantifikacije, Mebaneov model omogućava direktan izračun procenta glasova koji potiču iz sumnjivih procesa. Time se otvara prostor za preciznije diskusije: nije isto kada se u javnosti iznese tvrdnja da „izbori pokazuju nepravilnosti“ i kada se pokaže da, recimo, „45% glasova pobednika potiče iz klasa koje su identifikovane kao ballot stuffing ili ekstremna prevara“. Ti numerički rezultati na osnovu modela konačne mešavine biće izloženi i interpretirani u narednom delu ove četvrte objave.