1. Zašto je ponovljeno glasanje važno
Ponovljeno glasanje zvuči kao uska administrativna pojedinost, ali to nije. U proporcionalnim sistemima ponovljeno glasanje na samo jednom biračkom mestu može promeniti ne samo lokalni zbir na tom mestu, već i konačnu raspodelu mandata u celoj izbornoj jedinici. Upravo zato je ponovljeno glasanje važno pravnicima, izbornoj administraciji, posmatračima, novinarima i istraživačima izborne forenzike: kada se glasanje na jednom biračkom mestu poništi i ponovi, pravno relevantan rezultat više nije prvi zbir, već revidirani zbir nakon unošenja novog rezultata tog mesta. U Srbiji to nije hipotetičko pitanje. Posle lokalnih izbora iz marta 2026. određeno je ponovljeno glasanje na biračkom mestu broj 8 u Knjaževcu pošto je Viši sud u Zaječaru poništio prvobitno glasanje; lokalni medij je naveo da je ponovljeno glasanje zakazano za 29. april 2026. i da to biračko mesto ima 817 birača. Portal izborne administracije Srbije takođe je objavio dokumenta vezana za lokalne izbore u Knjaževcu 2026.
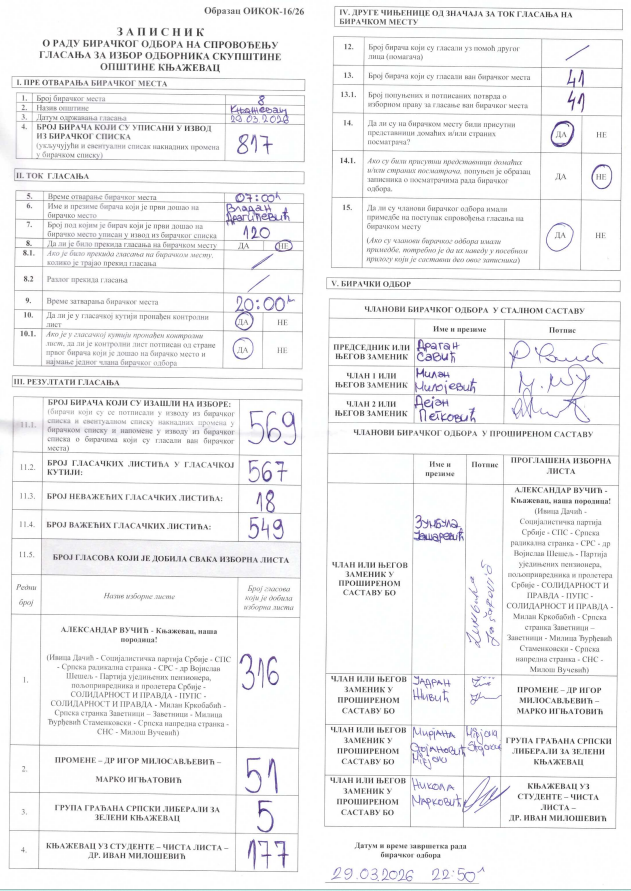
Za izbornu forenziku to je posebno važno zato što ponovljeno glasanje pokazuje gde se susreću pravna procedura i numerička struktura. Zakon može reći da se na određenom biračkom mestu glasanje mora ponoviti, ali analitički važno pitanje glasi: šta se zatim računa? Odgovor je jednostavan u načelu: stari rezultat sa poništenog biračkog mesta uklanja se, novi rezultat se unosi, a raspodela mandata računa se ponovo po istom izbornom pravilu. U srpskim lokalnim izborima to znači da se preračunavanje radi uz cenzus od 3% i sistem najvećeg količnika, uz posebno pravilo za manjinske liste kada je ono relevantno.
2. Osnovna logika: konačni važeći zbir, a ne prvi zbir
Središnja teorijska poenta je jednostavna. Ponovljeno glasanje ne stvara posebnu, paralelnu teoriju izbora. Ono pokreće obično preračunavanje po istoj izbornoj formuli koja je važila i za prvobitne izbore. U literaturi o izbornim sistemima i raspodeli mandata glasovi se pretvaraju u mandate pomoću pravila; ako se zakonski važeći zbir glasova promeni, i raspodela mandata se mehanički menja. Zato je problem ponovljenog glasanja najbolje tretirati kao poseban slučaj opšteg pravila: mandati slede konačni važeći zbir, a ne privremeni prvi zbir. To je potpuno u skladu i sa širom literaturom o izbornim sistemima i sa matematičkom logikom delilačkih metoda kao što je D’Hondt.
Vredi to reći sasvim jasno zato što javna rasprava često sklizne u neodređen jezik. Novinari mogu reći da su „izbori ponovljeni“, a politički akteri da „rezultat ostaje isti“ ili „rezultat se menja“, ali analitički ključni objekat je ukupni zbir izborne jedinice nakon zakonske korekcije. Kada se to razume, logika postaje providna. Nije nam potrebna nekakva mistična doktrina ponovljenog glasanja. Potrebno nam je pažljivo pravilo zamene i preračunavanja. Prvobitni rezultat na ponovljenom biračkom mestu zamenjuje se novim, sva ostala biračka mesta ostaju fiksna osim ako zakon ne kaže drugačije, a zatim se izborna formula primenjuje ponovo.
U srpskom zakonu o lokalnim izborima ova logika se vidi i u samoj strukturi normi. Član 58 propisuje da se glasanje na biračkom mestu ponavlja ako se rezultat na tom mestu ne može utvrditi ili ako je glasanje na tom mestu poništeno. Član 59 zatim jasno pokazuje da se opšti izveštaj o rezultatima sastavlja tek nakon ponovljenog glasanja i rešavanja odgovarajućih pravnih sredstava. Drugim rečima, sam zakon tretira ponovljeno glasanje ne kao dodatak rezultatu, već kao deo procesa koji proizvodi konačni važeći rezultat.
3. Matematička formulacija
Sada problem možemo formalno zapisati. Pretpostavimo da postoji \(P\) partija ili izbornih lista i \(S\) mandata koji se raspodeljuju u jednoj izbornoj jedinici. Neka je prvobitni zakonski evidentirani ukupan broj glasova za listu \(p\) jednak \(V_p\). Neka je \(R\) skup biračkih mesta na kojima se glasanje ponavlja. Za svako takvo mesto \(r \in R\), neka \(v_{pr}^{(stari)} \) označava stari rezultat liste \(p\), a \(v_{pr}^{(novi)} \) rezultat ponovljenog glasanja.
Korigovani ukupan broj glasova tada je:
$$ V_p^* = V_p – \sum_{r \in R} v_{pr}^{(stari)} + \sum_{r \in R} v_{pr}^{(novi)}. $$
Korigovani vektor mandata glasi:
$$ m^{*} = A(V_1^{*}, V_2^{*}, \dots, V_P^{*}; S) $$
gde \(A(\cdot)\) označava zakonski propisano pravilo raspodele mandata. Ako je pravilo D’Hondtovo, tada je \(A\) postupak najvećih proseka zasnovan na deliocima \( 1,2,3,\dots\). Ako postoji cenzus, on se primenjuje na korigovane ukupne glasove. Ako postoji posebno pravilo za manjinske liste, i ono se takođe mora primeniti na korigovane ukupne glasove.
Ova formulacija je jednostavna, ali veoma moćna. Ona kaže da je ponovljeno glasanje, matematički gledano, problem zamene praćen problemom raspodele. Prvo se stari vektor rezultata sa ponovljenih mesta zameni novim. Zatim se ponovo pokrene pravilo raspodele. Pomak u mandatima tada je:
$$ \Delta m = m^* – m^{(0)}, $$
gde je \(m^{(0)} \) prvobitni vektor mandata. Ako neko želi da modelira neizvesnost pre nego što ponovljeno glasanje bude održano, umesto poznatog novog rezultata može uvesti slučajni vektor i simulirati moguće ishode. Ali za pravne i administrativne potrebe odlučujući objekat ostaje realizovani korigovani zbir nakon što je ponovljeno glasanje stvarno sprovedeno.
4. Srpski lokalni izbori: šta se menja, a šta ne
Za srpske lokalne izbore pravni kontekst je bitan. Po važećem okviru lokalnih izbora, ponovljeno glasanje se sprovodi kada se rezultat na biračkom mestu ne može utvrditi ili kada je glasanje na tom mestu poništeno, i mora se održati u roku od deset dana od odgovarajuće odluke. Tek nakon ponovljenog glasanja i rešavanja pravnih sredstava finalizuje se opšti izveštaj o rezultatima lokalnih izbora. To znači da je pravno relevantna raspodela mandata ona koja je izračunata iz konačnih korigovanih zbirnih glasova, a ne iz prvobitno objavljenog opštinskog zbira.
Jednako je važno i samo pravilo raspodele mandata. Član 61 postavlja cenzus od 3% za učešće u raspodeli mandata. Član 62 zatim propisuje sistem najvećeg količnika: glasovi se dele uzastopnim celim brojevima od 1 do broja odbornika, količnici se rangiraju, a mandati dodeljuju prema najvećim količnicima. Isti član propisuje i pravilo razrešenja izjednačenja: ako dve liste imaju isti količnik za odlučujući mandat, prednost ima lista sa većim ukupnim brojem glasova. Zakon dalje sadrži i posebno pravilo za manjinske liste: kada je primenljivo, količnici manjinskih lista ispod 3% uvećavaju se za 35%. Sve su to detalji koji su važni, jer bi tekst o ponovljenom glasanju koji ignoriše cenzus, razrešenje izjednačenja ili posebna manjinska pravila bio nepotpun u srpskom kontekstu.
Tu postaje zanimljiva i sama implementacija. Mnogi jednostavni prikazi D’Hondtove metode u udžbenicima ili na internetu tačno računaju količnike, ali zanemaruju zakonsko pravilo razrešenja izjednačenja. To je prihvatljivo za elementarnu ilustraciju, ali nije uvek dovoljno za ozbiljnu analizu. U stvarnom slučaju ponovljenog glasanja, naročito kada je ponovljeno biračko mesto malo, izjednačeni količnici mogu se lako pojaviti kod poslednjeg mandata. Zato ozbiljna implementacija treba da obuhvati ne samo osnovno rangiranje D’Hondtovih količnika, već i pravilo razrešenja izjednačenja relevantno za datu jurisdikciju.
5. R implementacija
Kôd ispod rešava problem. On preračunava mandate nakon ponovljenog glasanja, uključuje parametar cenzusa, opcionu oznaku manjinskih lista i srpsko uvećanje količnika od 35%, a izričito obrađuje i srpsko pravilo za izjednačene količnike tako što prednost daje listi sa većim ukupnim brojem glasova.
# D'Hondt seat allocation / D'Hondt raspodela mandata
dhondt_repeated <- function(original_votes, repeat_old, repeat_new, seats,
threshold = 0.03, minority = NULL, bonus = 1.35) {
# original_votes = original municipality totals / originalni ukupni glasovi
# repeat_old = old votes from repeated stations / stari glasovi sa ponovljenih mesta
# repeat_new = new votes from repeated stations / novi glasovi sa ponovljenih mesta
# seats = total mandates / ukupan broj mandata
# Align party names / Uskladi nazive lista
parties <- names(original_votes)
repeat_old <- repeat_old[parties]
repeat_new <- repeat_new[parties]
# Default: no minority lists / Podrazumevano: nema manjinskih lista
if (is.null(minority)) minority <- rep(FALSE, length(parties))
names(minority) <- parties
# Corrected totals / Korigovani ukupni glasovi
corrected_votes <- original_votes - repeat_old + repeat_new
# Total valid votes / Ukupan broj važećih glasova
total_valid <- sum(corrected_votes)
# Threshold eligibility / Provera cenzusa
eligible <- (corrected_votes / total_valid) >= threshold | minority
# Build quotient table / Napravi tabelu količnika
qtab <- do.call(rbind, lapply(parties[eligible], function(p) {
divs <- seq_len(seats)
q <- unname(corrected_votes[p]) / divs
# Serbian minority uplift if applicable / Srpski manjinski bonus ako važi
if (minority[p] && (corrected_votes[p] / total_valid) < threshold) {
q <- q * bonus
}
data.frame(
party = rep(p, seats),
total_votes = rep(unname(corrected_votes[p]), seats),
divisor = divs,
quotient = q,
stringsAsFactors = FALSE
)
}))
# Rank quotients: quotient first, then higher total votes / Rangiraj količnike: količnik pa veći ukupan broj glasova
qtab <- qtab[order(-qtab$quotient, -qtab$total_votes, qtab$divisor, qtab$party), ]
# Allocate seats / Dodeli mandate
winners <- qtab[seq_len(seats), ]
seat_counts <- table(factor(winners$party, levels = parties))
# Return results / Vrati rezultate
list(
corrected_votes = corrected_votes,
seat_counts = seat_counts,
ranking = winners
)
}
# Example / Primer
original_votes <- c(A = 10000, B = 8000, C = 4000)
repeat_old <- c(A = 800, B = 400, C = 200)
repeat_new <- c(A = 500, B = 700, C = 300)
S <- 10
# Original seats / Originalni mandati
orig <- dhondt_repeated(
original_votes = original_votes,
repeat_old = c(A = 0, B = 0, C = 0),
repeat_new = c(A = 0, B = 0, C = 0),
seats = S,
threshold = 0
)
# Corrected seats / Korigovani mandati
corr <- dhondt_repeated(
original_votes = original_votes,
repeat_old = repeat_old,
repeat_new = repeat_new,
seats = S,
threshold = 0
)
# Print outputs / Prikaži izlaz
orig$seat_counts
corr$corrected_votes
corr$seat_counts
corr$seat_counts - orig$seat_countsOčekivani izlaz je:
# Print outputs / Prikaži izlaz
> orig$seat_counts
A B C
5 4 1
> corr$corrected_votes
A B C
9700 8300 4100
> corr$seat_counts
A B C
4 4 2
> corr$seat_counts - orig$seat_counts
A B C
-1 0 1Važne su dve stvari. Prvo, kôd ispravno kodira logiku zamene: ponovljeno biračko mesto ne dodaje nove glasove preko starih, već zamenjuje stare novim. Drugo, pravilo razrešenja izjednačenja je eksplicitno. To nije kozmetika. U ručno obrađenom primeru ispod, prvobitna raspodela zapravo sadrži izjednačenje na količniku 2000, pa pravno ozbiljna implementacija ne bi smela da prepusti tu odluku slučajnom redosledu softvera.
6. Ručna verifikacija primera
Sada proverimo primer ručno. Prvobitni ukupni glasovi: A = 10.000, B = 8.000 i C = 4.000; Mandata = 10
Relevantni D’Hondtovi količnici:
- A: 10000, 5000, 3333,33, 2500, 2000, 1666,67, …
- B: 8000, 4000, 2666,67, 2000, 1600, …
- C: 4000, 2000, 1333,33, …
Deset najvećih količnika su:
- 10000 (A)
- 8000 (B)
- 5000 (A)
- 4000 (B)
- 4000 (C)
- 3333,33 (A)
- 2666,67 (B)
- 2500 (A)
- 2000 (A)
- 2000 (B)
Zašto ne C za poslednji mandat? Zato što originalni primer sadrži trostruko izjednačenje na 2000 između A, B i C, a srpski zakon daje prednost listi sa većim ukupnim brojem glasova. Zato A dobija jedan od ta dva mandata ispred B i C, a B dobija drugi ispred C. Prema tome, prvobitna raspodela mandata je: A = 5, B = 4 i C = 1.
Sada primenimo ponovljeno glasanje.
Stari doprinos ponovljenog mesta: A = 800, B = 400 i C = 200.
Novi rezultat ponovljenog mesta: A = 500, B = 700 i C = 300.
Korigovani ukupni glasovi:
- A = 10000 – 800 + 500 = 9700
- B = 8000 – 400 + 700 = 8300
- C = 4000 – 200 + 300 = 4100
Korigovani D’Hondtovi količnici:
- A: 9700, 4850, 3233,33, 2425, 1940, …
- B: 8300, 4150, 2766,67, 2075, 1660, …
- C: 4100, 2050, 1366,67, …
Deset najvećih korigovanih količnika su:
- 9700 (A)
- 8300 (B)
- 4850 (A)
- 4150 (B)
- 4100 (C)
- 3233,33 (A)
- 2766,67 (B)
- 2425 (A)
- 2075 (B)
- 2050 (C)
Dakle, korigovana raspodela mandata je: A = 4, B = 4 i C = 2.
Pomak u mandatima je: A = – 1, B = 0 i C = +1.
Dakle, da: ispravno postavljena logika zaista daje novu D’Hondtovu raspodelu, a primer je sasvim dobra ilustracija kako relativno mala promena na ponovljenim biračkim mestima može promeniti konačnu raspodelu mandata. Ali primer otkriva i važnu dopunu: pravno robusna implementacija mora imati eksplicitno pravilo za razrešenje izjednačenja, a ne da zavisi od podrazumevanog redosleda u softveru.
7. Zašto je ovo važno za izbornu forenziku
Ponovljeno glasanje je važno za izbornu forenziku iz dva razloga. Prvi je očigledan: ako ponovljeno glasanje menja pravno relevantan rezultat, onda svaka ozbiljna postizborna analiza mora polaziti od konačnih važećih zbirnih glasova, a ne od preliminarnih. Drugi je suptilniji: ponovljeno glasanje može biti i dijagnostički događaj. Ono pokazuje koliko raspodela mandata može biti osetljiva na male promene u vektorima glasova, naročito pod delilačkim metodama. U veoma tesnoj lokalnoj trci nekoliko stotina glasova na jednom biračkom mestu možda neće promeniti samo procente; može promeniti mandat. To ponovljeno glasanje čini analitički važnim čak i kada ga javna rasprava tretira kao fusnotu.
Upravo zato ova tema pripada blogu o izbornoj forenzici. Izborna forenzika nije samo otkrivanje neobičnih obrazaca u agregatnim podacima. Ona je i razumevanje mehanike putem koje pravne korekcije, ponovljeno glasanje i izborne formule prevode osporene glasove u konačnu reprezentaciju. Teorija je jednostavna, ali posledice nisu. Ponovljeno glasanje je geografski malo, potencijalno veliko po posledicama i uvek podsetnik da reprezentacija zavisi ne samo od toga kako ljudi glasaju, već i od toga kako institucije broje, ispravljaju i pretvaraju glasove u mandate.
Literatura
Balinski, M. L., & Young, H. P. (1994). Apportionment. U K. J. Arrow, A. K. Sen, & K. Suzumura (ur.), Handbook of Social Choice and Welfare. Elsevier. doi:10.1016/S0927-0507(05)80096-9
de Córdoba, G. F., Fernández, J. R., & Torres, J. L. (2009). Institutionalizing uncertainty: The choice of electoral formulas. Public Choice, 141(3–4), 421–444. doi:10.1007/s11127-009-9460-9
Gallagher, M., & Mitchell, P. (ur.). (2005). The Politics of Electoral Systems. Oxford University Press. doi:10.1093/0199257566.001.0001
Kohler, U. (2012). Apportionment methods. The Stata Journal, 12(3), 375–392. doi:10.1177/1536867X1201200303
Medzihorsky, J. (2019). Rethinking the D’Hondt method. Political Research Exchange, 1(1), članak 1625712. doi:10.1080/2474736X.2019.1625712
Dve napomene. Prvo, neposredna literatura sa DOI koja je baš posvećena delimičnom ponovljenom glasanju i ponovnom preračunavanju mandata prilično je oskudna; zato je formalizacija u ovom tekstu izvedena iz opšte logike agregiranja glasova, važećeg izbornog prava i standardne literature o raspodeli mandata. Drugo, primer sa originalnim glasovima 10.000–8.000–4.000 koristan je upravo zato što sadrži izjednačenje u originalnoj raspodeli i time pokazuje da “tačan D’Hondt” u stvarnoj praksi često znači: D’Hondt plus zakonsko pravilo za razrešenje izjednačenja.
Python verzija
from typing import Dict, List, Optional, Any
def dhondt_repeated(
original_votes: Dict[str, float],
repeat_old: Dict[str, float],
repeat_new: Dict[str, float],
seats: int,
threshold: float = 0.03,
minority: Optional[Dict[str, bool]] = None,
bonus: float = 1.35
) -> Dict[str, Any]:
# original_votes = original municipality totals / originalni ukupni glasovi
# repeat_old = old votes from repeated stations / stari glasovi sa ponovljenih mesta
# repeat_new = new votes from repeated stations / novi glasovi sa ponovljenih mesta
# seats = total mandates / ukupan broj mandata
# Align party names / Uskladi nazive lista
parties: List[str] = list(original_votes.keys())
# Default missing values to zero / Nedostajuće vrednosti postavi na nulu
repeat_old_aligned = {p: repeat_old.get(p, 0) for p in parties}
repeat_new_aligned = {p: repeat_new.get(p, 0) for p in parties}
# Default: no minority lists / Podrazumevano: nema manjinskih lista
if minority is None:
minority = {p: False for p in parties}
else:
minority = {p: minority.get(p, False) for p in parties}
# Corrected totals / Korigovani ukupni glasovi
corrected_votes = {
p: original_votes[p] - repeat_old_aligned[p] + repeat_new_aligned[p]
for p in parties
}
# Total valid votes / Ukupan broj važećih glasova
total_valid = sum(corrected_votes.values())
# Threshold eligibility / Provera cenzusa
eligible = {
p: ((corrected_votes[p] / total_valid) >= threshold) or minority[p]
for p in parties
}
# Build quotient table / Napravi tabelu količnika
qtab: List[Dict[str, Any]] = []
for p in parties:
if not eligible[p]:
continue
for divisor in range(1, seats + 1):
quotient = corrected_votes[p] / divisor
# Serbian minority uplift if applicable / Srpski manjinski bonus ako važi
if minority[p] and (corrected_votes[p] / total_valid) < threshold:
quotient *= bonus
qtab.append({
"party": p,
"total_votes": corrected_votes[p],
"divisor": divisor,
"quotient": quotient
})
# Rank quotients: quotient first, then higher total votes / Rangiraj količnike: količnik pa veći ukupan broj glasova
qtab_sorted = sorted(
qtab,
key=lambda row: (-row["quotient"], -row["total_votes"], row["divisor"], row["party"])
)
# Allocate seats / Dodeli mandate
winners = qtab_sorted[:seats]
seat_counts = {p: 0 for p in parties}
for row in winners:
seat_counts[row["party"]] += 1
# Return results / Vrati rezultate
return {
"corrected_votes": corrected_votes,
"seat_counts": seat_counts,
"ranking": winners
}
# Example / Primer
original_votes = {"A": 10000, "B": 8000, "C": 4000}
repeat_old = {"A": 800, "B": 400, "C": 200}
repeat_new = {"A": 500, "B": 700, "C": 300}
S = 10
# Original seats / Originalni mandati
orig = dhondt_repeated(
original_votes=original_votes,
repeat_old={"A": 0, "B": 0, "C": 0},
repeat_new={"A": 0, "B": 0, "C": 0},
seats=S,
threshold=0
)
# Corrected seats / Korigovani mandati
corr = dhondt_repeated(
original_votes=original_votes,
repeat_old=repeat_old,
repeat_new=repeat_new,
seats=S,
threshold=0
)
print("Original seats / Originalni mandati:")
print(orig["seat_counts"])
print("\nCorrected vote totals / Korigovani ukupni glasovi:")
print(corr["corrected_votes"])
print("\nCorrected seats / Korigovani mandati:")
print(corr["seat_counts"])
print("\nMandate shift / Promena mandata:")
shift = {p: corr["seat_counts"][p] - orig["seat_counts"][p] for p in original_votes}
print(shift)
print("\nTop quotients after correction / Najveći količnici posle korekcije:")
for row in corr["ranking"]:
print(row) Očekivani izlaz je:
Original seats / Originalni mandati:
{'A': 5, 'B': 4, 'C': 1}
Corrected vote totals / Korigovani ukupni glasovi:
{'A': 9700, 'B': 8300, 'C': 4100}
Corrected seats / Korigovani mandati:
{'A': 4, 'B': 4, 'C': 2}
Mandate shift / Promena mandata:
{'A': -1, 'B': 0, 'C': 1}